Fall 2025 • Machine Learning Course
PyTorch Domain Classifier
The Challenge
Most machine learning assignments ask you to build a model that generalizes well to new, unseen data. This one flipped that goal. The task was to build a model that performs accurately on a specific set of images (in-domain), while deliberately performing poorly, near random chance, on a second unrelated set (out-of-domain). Achieving this intentionally is a harder design problem than it sounds.
Our Approach: Two Specialized Models
Rather than trying to train one model to satisfy two opposing objectives at once, we split the problem into two independent models working in sequence.
The first model, which we called the Bodyguard, acts as a gatekeeper. Its only job is to look at an image and decide whether it belongs to the in-domain set or not. It outputs a confidence score. If the score is high enough (above a tuned threshold), the image is passed to the second model.
The second model, the Expert, is a 10-class classifier trained exclusively on in-domain images. It never sees out-of-domain data during training, so its knowledge is intentionally narrow. When the Bodyguard determines an image is out-of-domain, the Expert is skipped entirely and the system returns a random class prediction, ensuring out-of-domain accuracy converges to approximately 10%.
Both models are built on the ResNet-18 architecture, trained from scratch without any pretrained weights, as required by the assignment constraints.
Finding the Right Training Settings
We ran a grid of experiments to determine the best optimizer and weight decay for each model, training each configuration for 128 epochs with a learning rate of 0.01 and a CosineAnnealingLR scheduler.
Table 1: Expert Model Accuracy under Various Optimizers and Weight Decay Values
| Optimizer | Weight Decay (λ) | In-Domain Accuracy (%) | OoD Accuracy (%) |
|---|---|---|---|
| SGD | 0.001 | 54.25 | 39.99 |
| SGD | 0.01 | 53.96 | 38.10 |
| SGD | 0.1 | 53.81 | 36.77 |
| SGD | 0.5 | 14.45 | 11.36 |
| AdamW | 0.001 | 55.33 | 41.29 |
| AdamW | 0.01 | 55.91 | 38.04 |
| AdamW | 0.1 | 56.79 | 38.09 |
| AdamW | 0.5 | 52.85 | 33.90 |
AdamW with weight decay 0.1 gave the best in-domain accuracy and was selected for the Expert model.
Table 2: Effect of Learning Rate Scheduler on Expert Model Accuracy
| Scheduler | In-Domain Accuracy (%) | OoD Accuracy (%) |
|---|---|---|
| None | 45.26 | 31.06 |
| CosineAnnealingLR | 57.98 | 41.41 |
Adding the CosineAnnealingLR scheduler increased in-domain accuracy by over 12 percentage points, confirming its necessity at high epoch counts.
Table 3: Bodyguard (OOD Detector) Accuracy under Various Optimizers and Weight Decay Values
| Optimizer | Weight Decay (λ) | Accuracy (%) |
|---|---|---|
| SGD | 0.001 | 67.82 |
| SGD | 0.01 | 64.44 |
| SGD | 0.1 | 60.92 |
| SGD | 0.5 | 56.47 |
| AdamW | 0.001 | 65.46 |
| AdamW | 0.01 | 68.18 |
| AdamW | 0.1 | 65.05 |
| AdamW | 0.5 | 56.47 |
AdamW with weight decay 0.01 gave the highest domain detection accuracy for the Bodyguard model.
Combining the Models
With both models trained, we introduced a confidence threshold for the Bodyguard. Rather than taking its raw argmax prediction, we only treat an image as in-domain if the Bodyguard's softmax probability exceeds the threshold. This prevents the Bodyguard from misclassifying borderline out-of-domain images and accidentally routing them to the Expert.
We tested threshold values from 0 to 0.18. The charts below show the effect on both accuracy curves as the threshold increases. A threshold around 0.06 to 0.08 struck the best balance, cutting out-of-domain accuracy by roughly 9 percentage points while reducing in-domain accuracy by only 4. We settled on a final threshold of 0.07.
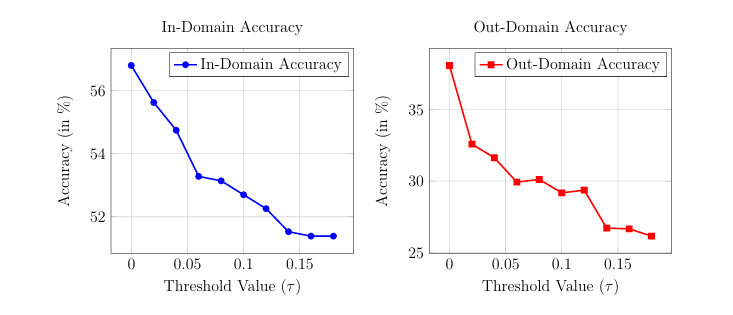
Left: In-Domain accuracy decreases gradually as the threshold rises. Right: Out-of-Domain accuracy drops much faster, which is the desired behavior.
Final Results
| In-Domain Accuracy (%) | Out-of-Domain Accuracy (%) |
|---|---|
| 52.263 | 27.030 |
The combined pipeline achieves solid in-domain classification while keeping out-of-domain accuracy well below 30%, far from the 50%+ that a neutral model would produce on the same data.